Goal: Explore Imago datasets programmatically and replicate analyses across products.
Training Approach: The instructor will first demonstrate the workflow using one example dataset. Participants will then repeat the steps with alternative dataset combinations to practice transferring the workflow across products.
We’ll start the demo with Summer Maximum Temperature and Health Deprivation 2025.
Once you are comfortable with the workflow, feel free to try it out on other datasets—for example, other temperature indicators, flood risk, the sun probability framework or particular IMD domains—to explore different kinds of questions.
Installing packages
We will start by loading core packages for working with spatial data. See detailed description of R and Python;
# Core data handling and plottinglibrary(tidyverse) # Data manipulation + ggplot2
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.2.0
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.5 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(dplyr) # (Loaded with tidyverse, listed here for clarity)library(readr) # Fast reading of CSVslibrary(readxl) # Reading Excel files# Spatial data and mappinglibrary(sf) # Simple Features: work with spatial data
Linking to GEOS 3.12.1, GDAL 3.8.4, PROJ 9.4.0; sf_use_s2() is TRUE
library(tmap) # Thematic mappinglibrary(geojsonsf) # Convert between GeoJSON and sf objectslibrary(osmdata) # Access OpenStreetMap data
Data (c) OpenStreetMap contributors, ODbL 1.0. https://www.openstreetmap.org/copyright
library(basemapR) # Static basemaps for mapping# Plot styling and layoutlibrary(viridis) # Colorblind-friendly palettes
Loading required package: viridisLite
library(cowplot) # Combining and arranging plots
Attaching package: 'cowplot'
The following object is masked from 'package:lubridate':
stamp
# File system utilitieslibrary(fs) # File and directory helpers
library(reticulate)
# Standard libraryimport os # File paths, environmentimport tempfile # Temporary filesimport zipfile # Extracting ZIP archives# Data & geospatialimport numpy as npimport pandas as pdimport geopandas as gpd# Plottingimport matplotlib.pyplot as pltfrom matplotlib.patches import Patchfrom mpl_toolkits.axes_grid1.inset_locator import inset_axesfrom matplotlib import cmimport seaborn as sns# Statisticsimport statsmodels.api as smfrom scipy import statsfrom scipy.stats import pearsonr# Networkingimport requests
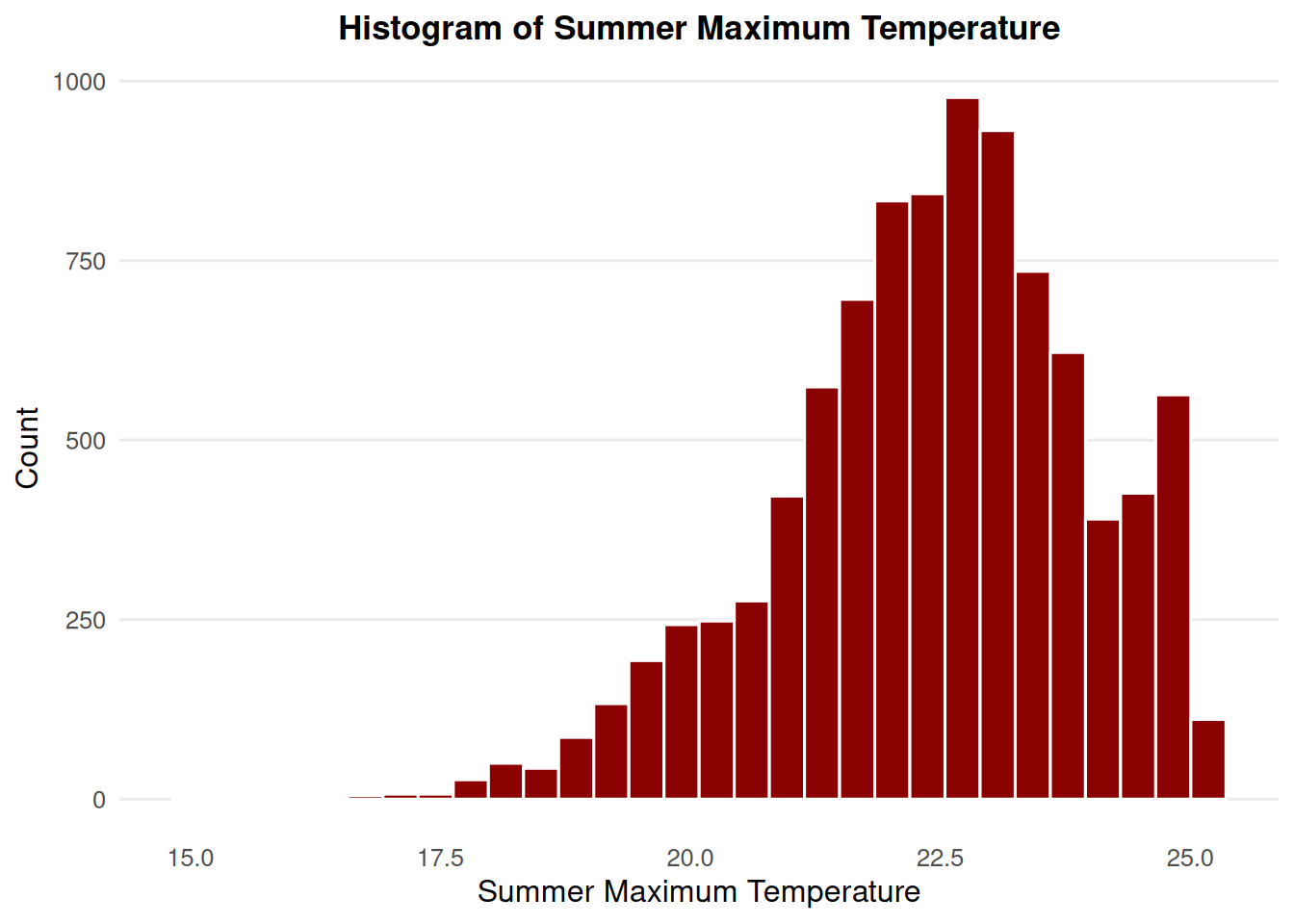
ggplot(msoa_temp, aes(x = summer_max_tmp)) +geom_histogram(bins =30, color ="white", fill ="darkred") +labs(title ="Histogram of Summer Maximum Temperature",x ="Summer Maximum Temperature",y ="Count" ) +theme_minimal(base_size =12) +theme(plot.title =element_text(face ="bold", size =13, hjust =0.5),panel.grid.minor =element_blank(),panel.grid.major.x =element_blank() )
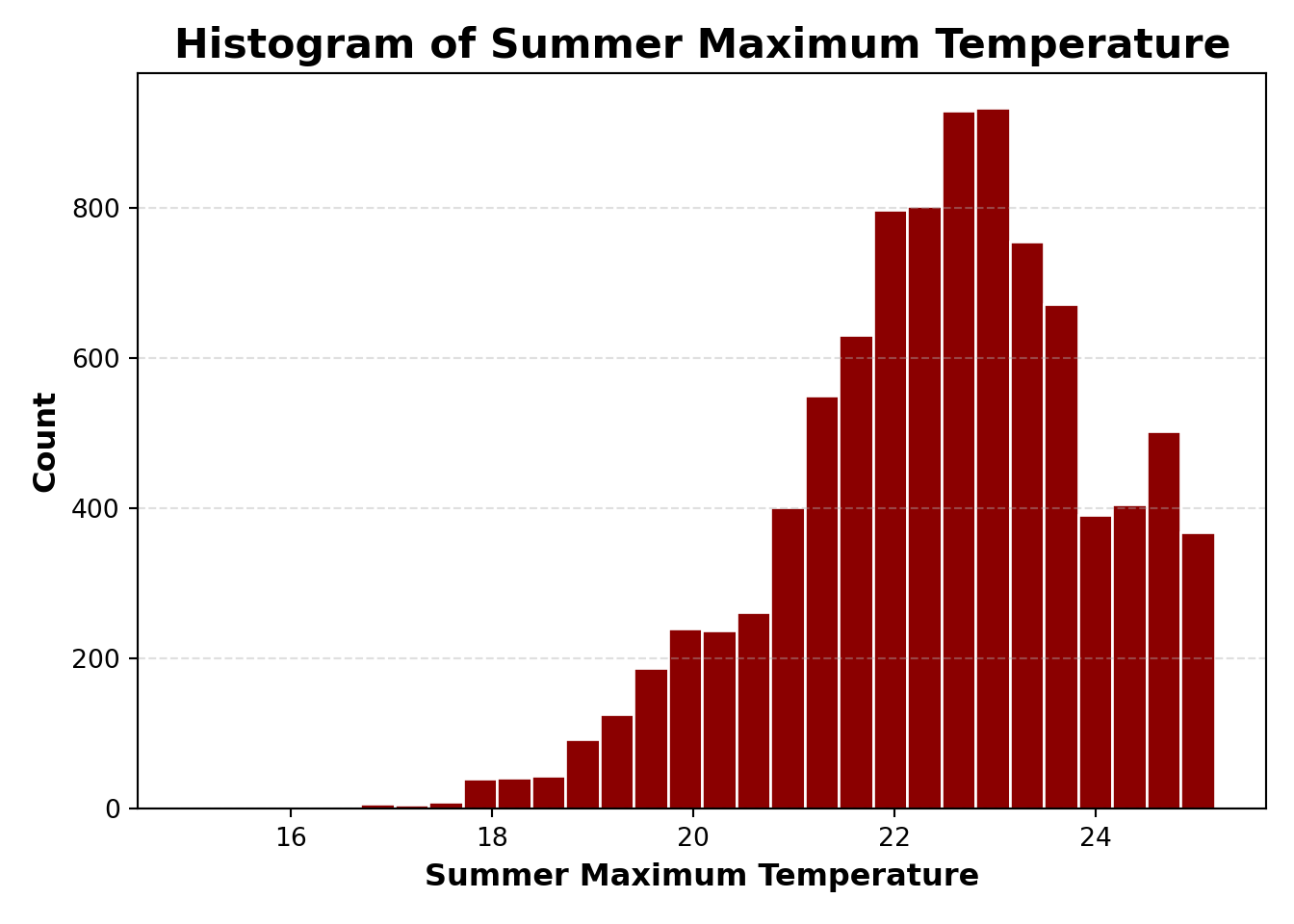
fig, ax = plt.subplots()ax.hist( msoa_temp["summer_max_tmp"], bins=30, edgecolor="white", color="darkred")# Labels and titleax.set_title("Histogram of Summer Maximum Temperature", fontsize=16, fontweight="bold", loc="center")ax.set_xlabel("Summer Maximum Temperature", fontsize=12, fontweight="bold")ax.set_ylabel("Count", fontsize=12, fontweight="bold")# Minimal-style adjustmentsax.grid(axis="y", linestyle="--", alpha=0.4)ax.grid(axis="x", visible=False)ax.set_facecolor("white")fig.set_facecolor("white")plt.tight_layout()plt.show()
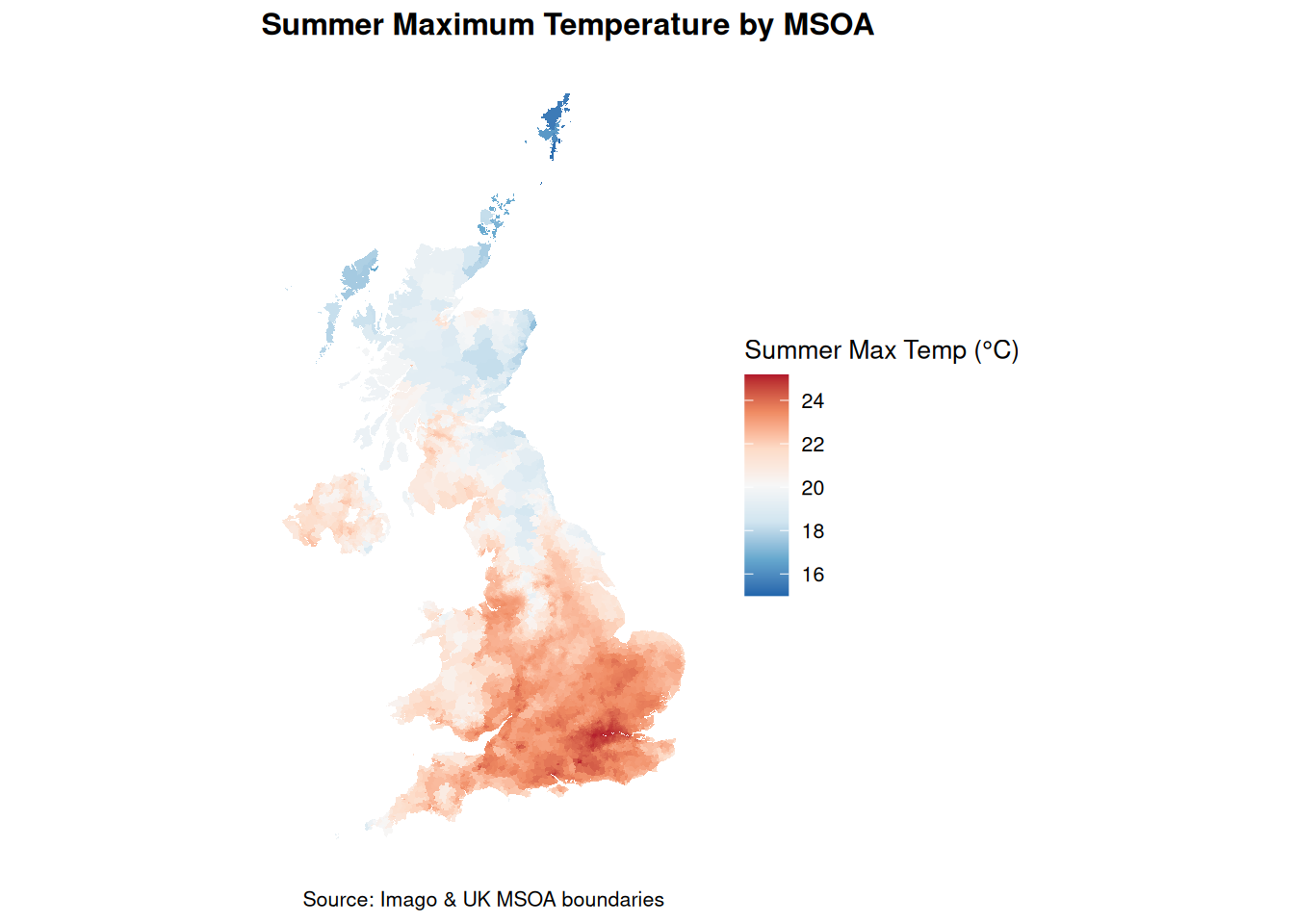
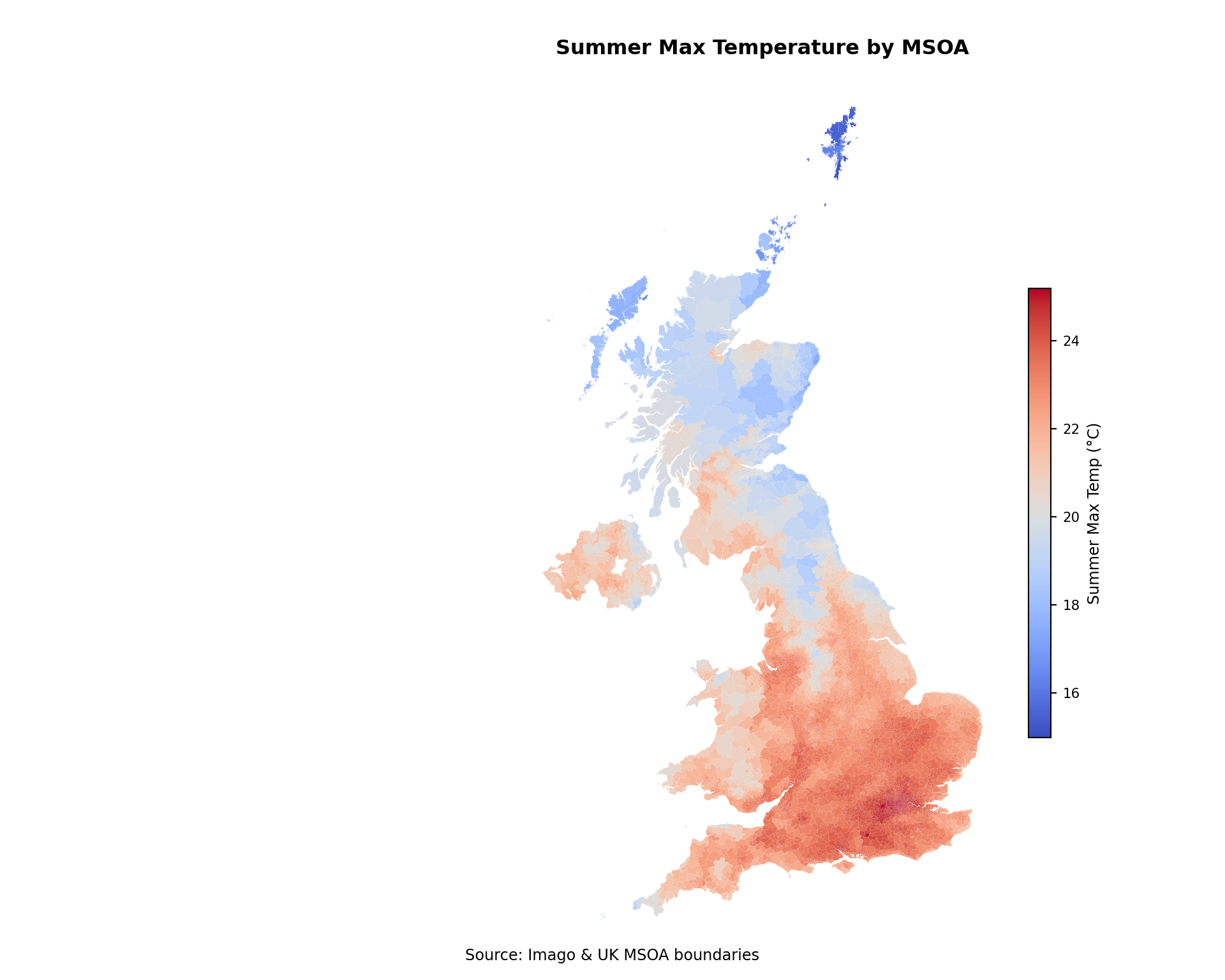
Mapping by local area
Mapping temperature across MSOAs allows us to see spatial variation and identify hotter areas during summer. Here, we visualise summer maximum temperatures in degrees Celsius.
[1] "LSOA code (2021)"
[2] "LSOA name (2021)"
[3] "Local Authority District code (2024)"
[4] "Local Authority District name (2024)"
[5] "Index of Multiple Deprivation (IMD) Rank (where 1 is most deprived)"
[6] "Index of Multiple Deprivation (IMD) Decile (where 1 is most deprived 10% of LSOAs)"
[7] "Income Rank (where 1 is most deprived)"
[8] "Income Decile (where 1 is most deprived 10% of LSOAs)"
[9] "Employment Rank (where 1 is most deprived)"
[10] "Employment Decile (where 1 is most deprived 10% of LSOAs)"
[11] "Education, Skills and Training Rank (where 1 is most deprived)"
[12] "Education, Skills and Training Decile (where 1 is most deprived 10% of LSOAs)"
[13] "Health Deprivation and Disability Rank (where 1 is most deprived)"
[14] "Health Deprivation and Disability Decile (where 1 is most deprived 10% of LSOAs)"
[15] "Crime Rank (where 1 is most deprived)"
[16] "Crime Decile (where 1 is most deprived 10% of LSOAs)"
[17] "Barriers to Housing and Services Rank (where 1 is most deprived)"
[18] "Barriers to Housing and Services Decile (where 1 is most deprived 10% of LSOAs)"
[19] "Living Environment Rank (where 1 is most deprived)"
[20] "Living Environment Decile (where 1 is most deprived 10% of LSOAs)"
# Create a temporary file with .xlsx extensiontmp_file = tempfile.NamedTemporaryFile(delete=False, suffix=".xlsx").name# Downloadurl ="https://assets.publishing.service.gov.uk/media/691decfae39a085bda43efcd/File_2_IoD2025_Domains_of_Deprivation.xlsx"r = requests.get(url)withopen(tmp_file, "wb") as f: f.write(r.content)
4337372
# Read Excel sheet & Clean up temp fileimd = pd.read_excel(tmp_file, sheet_name="IoD2025 Domains")os.remove(tmp_file)# Now imd existsprint(imd.columns.tolist())
['LSOA code (2021)', 'LSOA name (2021)', 'Local Authority District code (2024)', 'Local Authority District name (2024)', 'Index of Multiple Deprivation (IMD) Rank (where 1 is most deprived)', 'Index of Multiple Deprivation (IMD) Decile (where 1 is most deprived 10% of LSOAs)', 'Income Rank (where 1 is most deprived)', 'Income Decile (where 1 is most deprived 10% of LSOAs)', 'Employment Rank (where 1 is most deprived)', 'Employment Decile (where 1 is most deprived 10% of LSOAs)', 'Education, Skills and Training Rank (where 1 is most deprived)', 'Education, Skills and Training Decile (where 1 is most deprived 10% of LSOAs)', 'Health Deprivation and Disability Rank (where 1 is most deprived)', 'Health Deprivation and Disability Decile (where 1 is most deprived 10% of LSOAs)', 'Crime Rank (where 1 is most deprived)', 'Crime Decile (where 1 is most deprived 10% of LSOAs)', 'Barriers to Housing and Services Rank (where 1 is most deprived)', 'Barriers to Housing and Services Decile (where 1 is most deprived 10% of LSOAs)', 'Living Environment Rank (where 1 is most deprived)', 'Living Environment Decile (where 1 is most deprived 10% of LSOAs)']
Aggregate up to MSOA
To combine temperature data (held at MSOA level) with deprivation data (held at LSOA level), we use the Postcode → OA (2021) → LSOA → MSOA → Local Authority District (LAD) best-fit lookup published by the Office for National Statistics (ONS):
This provides consistent, authoritative geographic relationships between postcode units and statistical areas. It enables us to link LSOA-level IMD data to MSOA-level heat estimates and then calculate MSOA-level average deprivation scores.
# Unzipwith zipfile.ZipFile(zip_file, "r") as z: z.extractall(unzipped_dir)# Delete ZIP immediatelyos.remove(zip_file)# Locate lookup CSVlookup_path =Nonefor root, dirs, files in os.walk(unzipped_dir):forfilein files:iffile.lower().endswith(".csv"): lookup_path = os.path.join(root, file)breakif lookup_path:breakif lookup_path isNone:raiseFileNotFoundError("No CSV found in the downloaded ZIP.")# Load lookup tableLSOA21_MSOA21 = pd.read_csv(lookup_path)# Keep only necessary columnsLSOA21_MSOA21 = LSOA21_MSOA21[ ["lsoa21cd", "msoa21cd", "ladcd", "lsoa21nm", "msoa21nm", "ladnm"]].drop_duplicates(subset="lsoa21cd")# Join to IMDlsoa_msoa_imd = LSOA21_MSOA21.merge( imd, how="left", left_on="lsoa21cd", right_on="LSOA code (2021)")
Join IMD
Keep only the relevant columns from the LSOA lookup & IMD dataset. Rename the long IMD column names to shorter, convenient names: health_rank and health_decile.
lsoa_msoa_imd_clean <- lsoa_msoa_imd %>%select( lsoa21cd, msoa21cd, ladcd, lsoa21nm, msoa21nm, ladnm,`Health Deprivation and Disability Rank (where 1 is most deprived)`,`Health Deprivation and Disability Decile (where 1 is most deprived 10% of LSOAs)` ) %>%rename(health_rank =`Health Deprivation and Disability Rank (where 1 is most deprived)`,health_decile =`Health Deprivation and Disability Decile (where 1 is most deprived 10% of LSOAs)` )
# Select the required columnslsoa_msoa_imd_clean = lsoa_msoa_imd[ ["lsoa21cd","msoa21cd","ladcd","lsoa21nm","msoa21nm","ladnm","Health Deprivation and Disability Rank (where 1 is most deprived)","Health Deprivation and Disability Decile (where 1 is most deprived 10% of LSOAs)" ]].rename( columns={"Health Deprivation and Disability Rank (where 1 is most deprived)": "health_rank","Health Deprivation and Disability Decile (where 1 is most deprived 10% of LSOAs)": "health_decile" })
As IMD is only for England, check number of MSOAs that are covered.
# Strip whitespace and ensure string type for MSOA codesmsoa_imd_agg['msoa21cd'] = msoa_imd_agg['msoa21cd'].astype(str).str.strip()msoa_temp['msoa21cd'] = msoa_temp['MSOA21C'].astype(str).str.strip()
Join the aggregated IMD data with the MSOA-level heat dataset by MSOA code. The final dataset contains:
msoa_final <- msoa_imd_agg %>%left_join(msoa_temp %>%select(msoa21cd, summer_max_tmp), by ="msoa21cd")
temp_cols = ["msoa21cd", "summer_max_tmp"]# Left join on 'msoa21cd'msoa_final = msoa_imd_agg.merge( msoa_temp[temp_cols], how="left", on="msoa21cd")
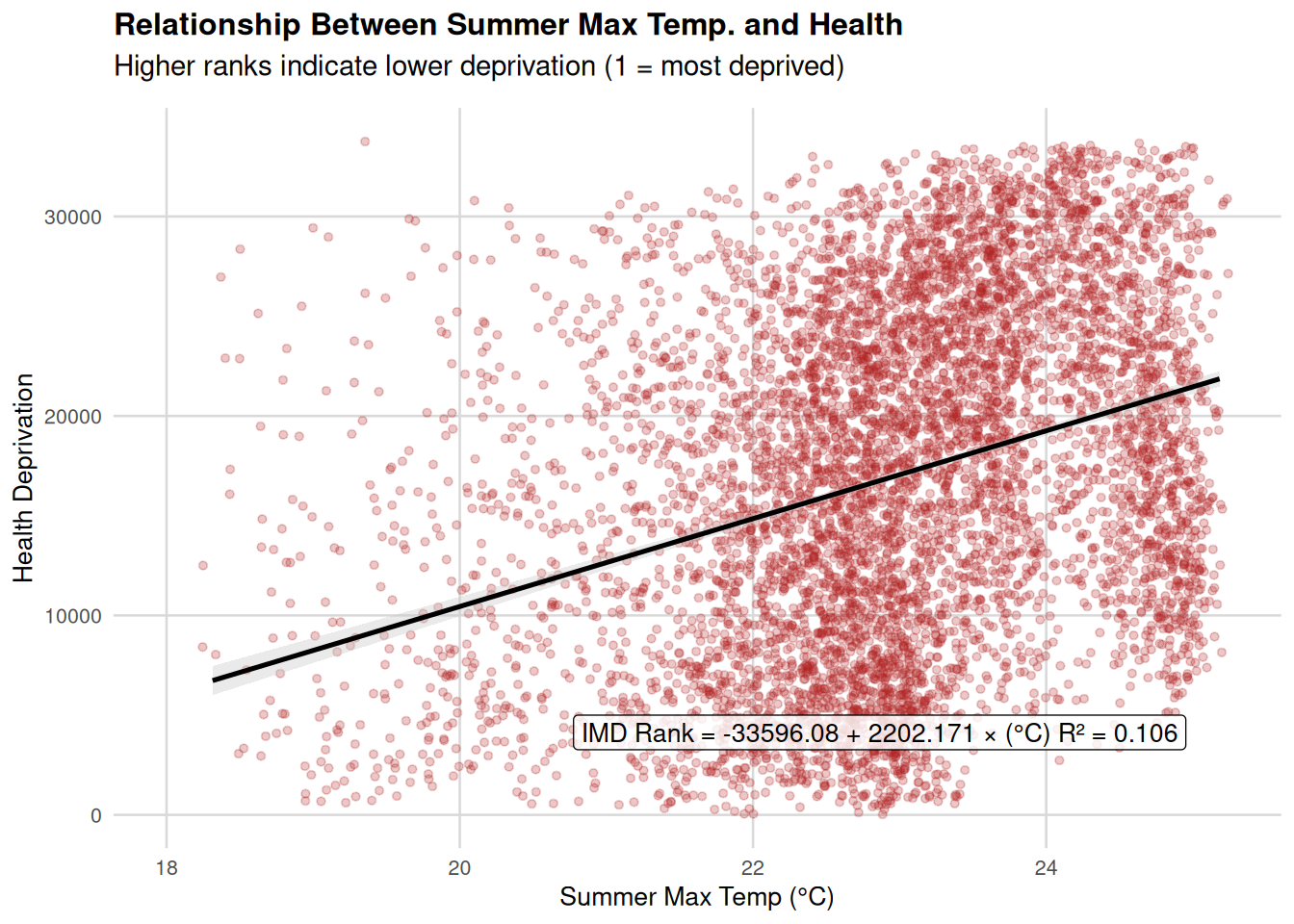
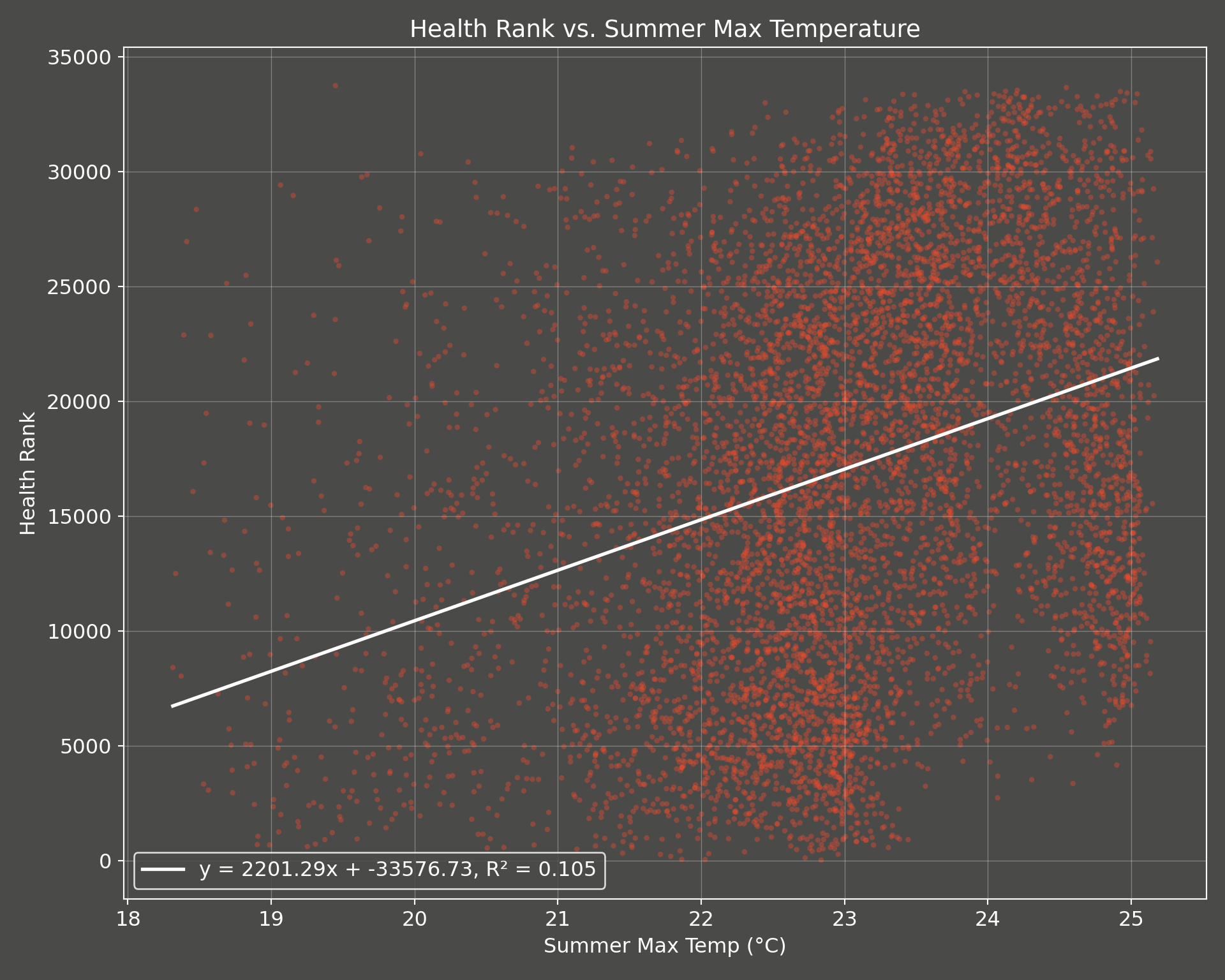
Create a scatterplot: exposure to heat vs. deprivation decile
Next, we explore the relationship between summer maximum temperature and health deprivation. We can visualize this using a scatterplot and then quantify it with a simple linear regression model, where the health rank is the outcome and summer maximum temperature is the predictor.
Note
In reality, multiple factors influence deprivation, so this is a simplified illustration. Additional variables would likely play a role in a more complete analysis.
If we want to examine the specific relationship between hot temperature and health deprivation in a causal way, we would also need to account for confounding factors that could influence both temperature exposure and health These might include:
• Socioeconomic and demographic factors: income, employment, education levels, age distribution, and ethnicity.
• Housing characteristics: building quality, insulation, heating systems, tenure (owned vs rented), and urban density.
• Environmental features: altitude, proximity to water, green space, and urban heat island effects.
• Health and vulnerability indicators: prevalence of chronic illnesses, respiratory conditions, or other factors affecting resilience to cold.
• Infrastructure and access: availability of public transport, energy affordability, and access to healthcare or social services.
The code below:
Fits the model,
Extracts the regression equation and R² value, and
Visualise the relationship using a scatterplot with a fitted trend line and an annotated equation.
Pearson's product-moment correlation
data: msoa_final$summer_max_tmp and msoa_final$health_rank_msoa
t = 28.435, df = 6854, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.3034996 0.3458496
sample estimates:
cor
0.3248374
# Drop missing values for the two columnsx = msoa_final['summer_max_tmp']y = msoa_final['health_rank_msoa']mask = x.notna() & y.notna()# Compute Pearson correlationcorr_coef, p_value = pearsonr(x[mask], y[mask])print(f"Pearson correlation: {corr_coef:.3f}")
Pearson correlation: 0.325
print(f"P-value: {p_value:.3g}")
P-value: 4.86e-168
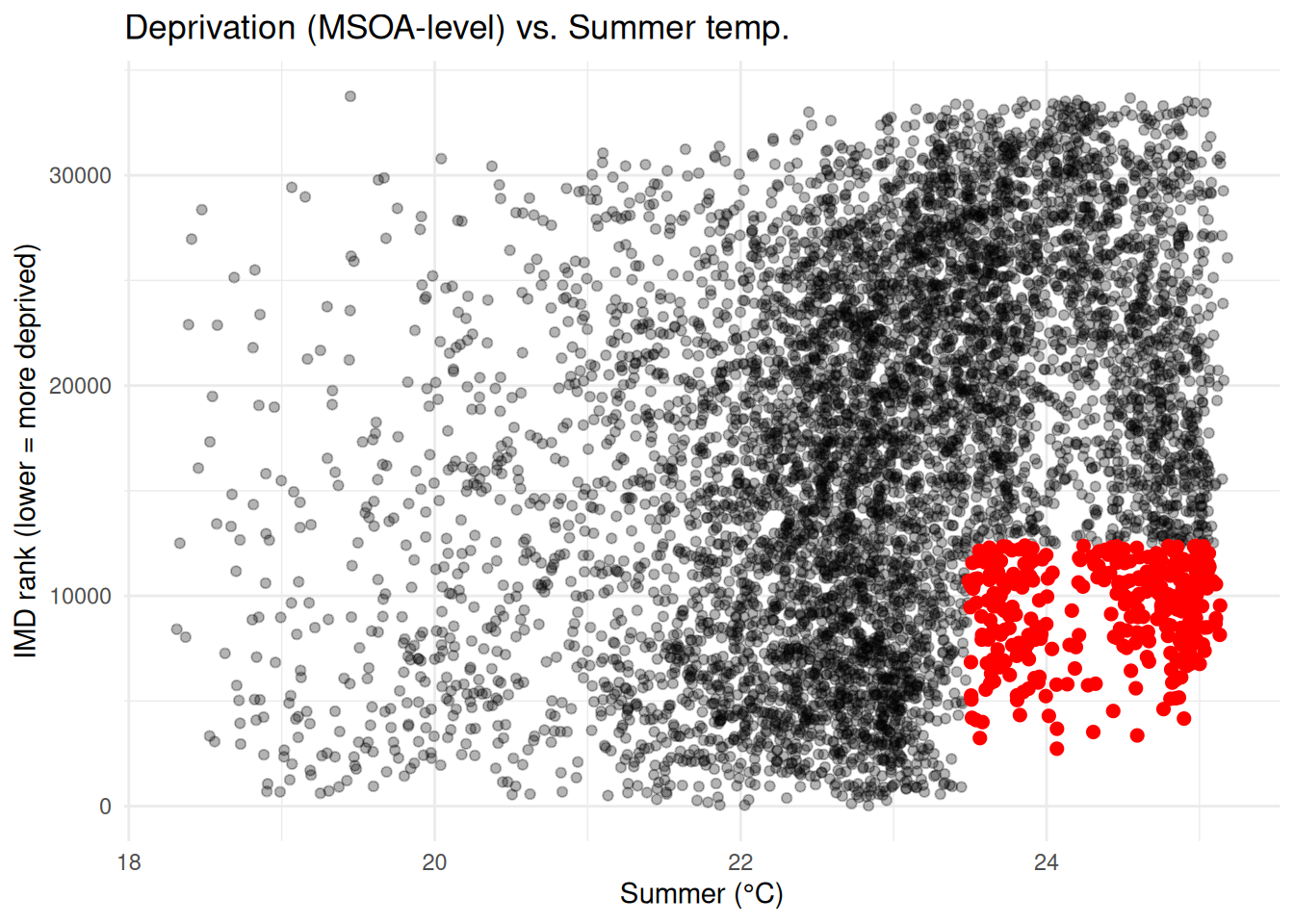
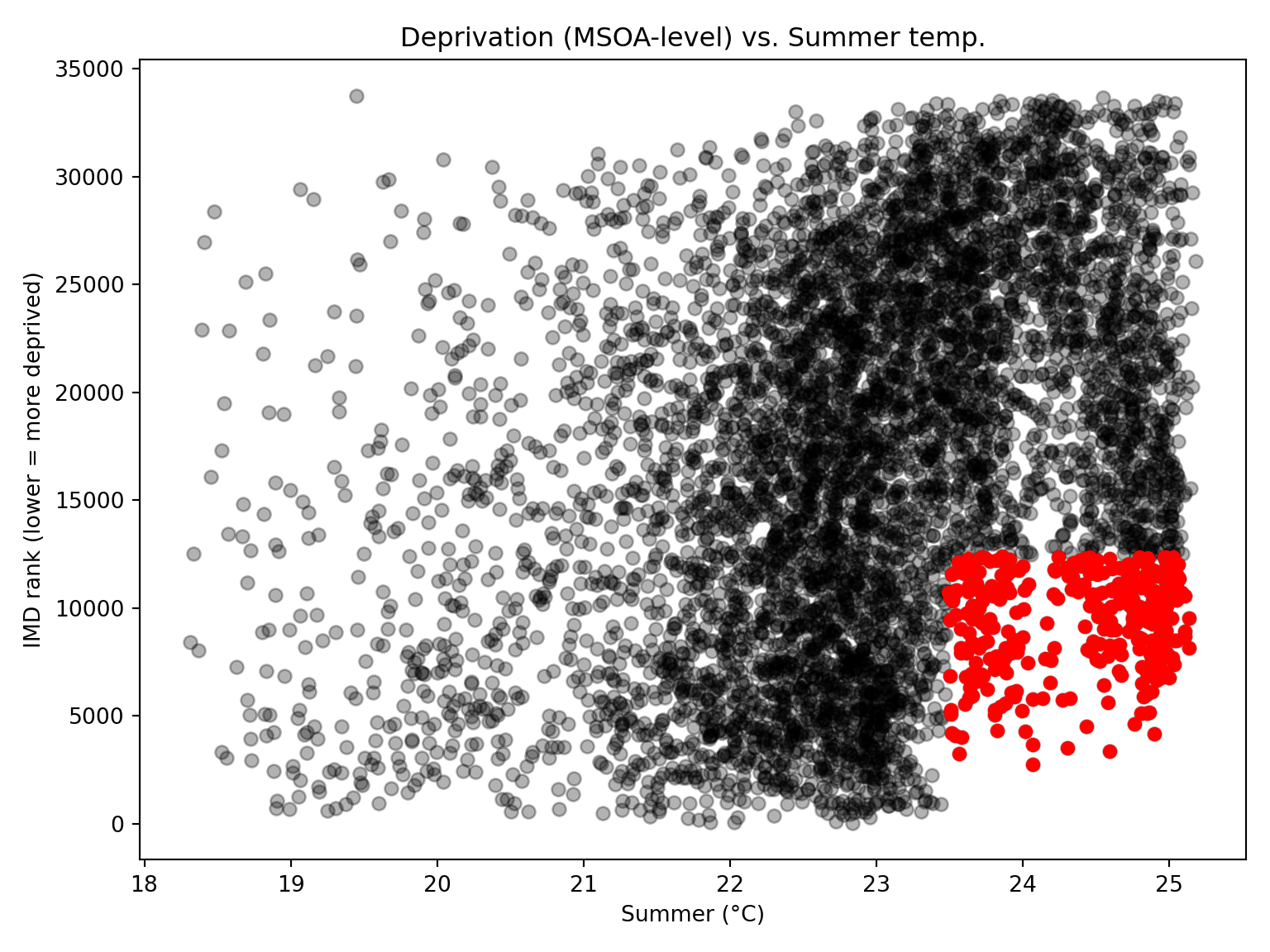
Exploring IMD rank quintiles
First, we remove MSOAs with missing health rank or summer maximum temperature values to avoid NA values flowing through the analysis. The quintiles are created (1 = most deprived MSOAs, 5 = least deprived).
msoa_hotspots = msoa_final_clean.copy()# Create deciles (5 groups here)msoa_hotspots["summertemp_decile"] = pd.qcut( msoa_hotspots["summer_max_tmp"], q=3, labels=False) +1# labels msoa_hotspots["health_decile"] = pd.qcut(-msoa_hotspots["health_rank_msoa"], q=3, labels=False) +1# labels# Filter to the hottest temps & most deprivedmsoa_hotspots = msoa_hotspots[ (msoa_hotspots["summertemp_decile"] ==3) & (msoa_hotspots["health_decile"] ==3)]
Scatter plot with quadrants (best to show inequality trend)
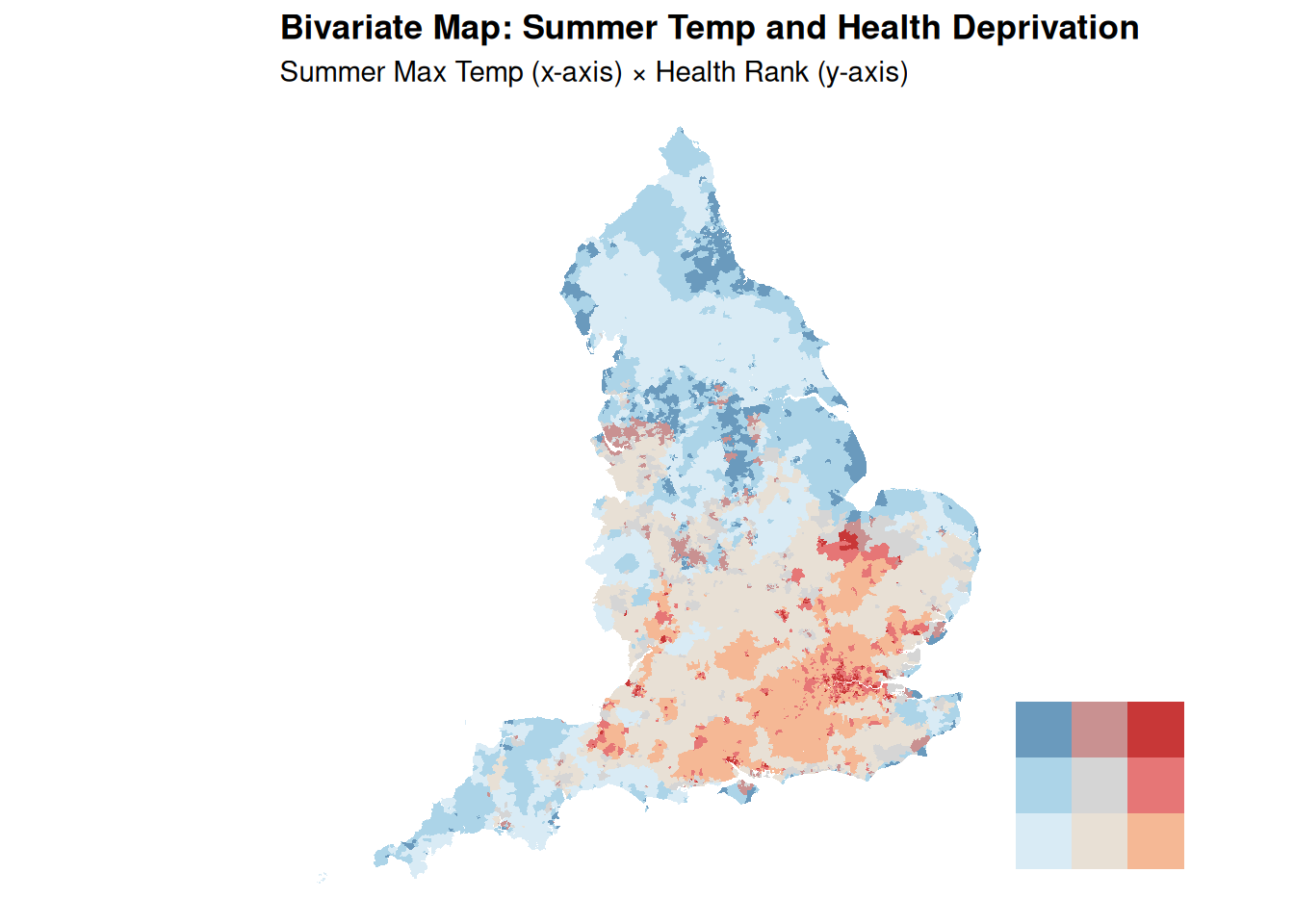
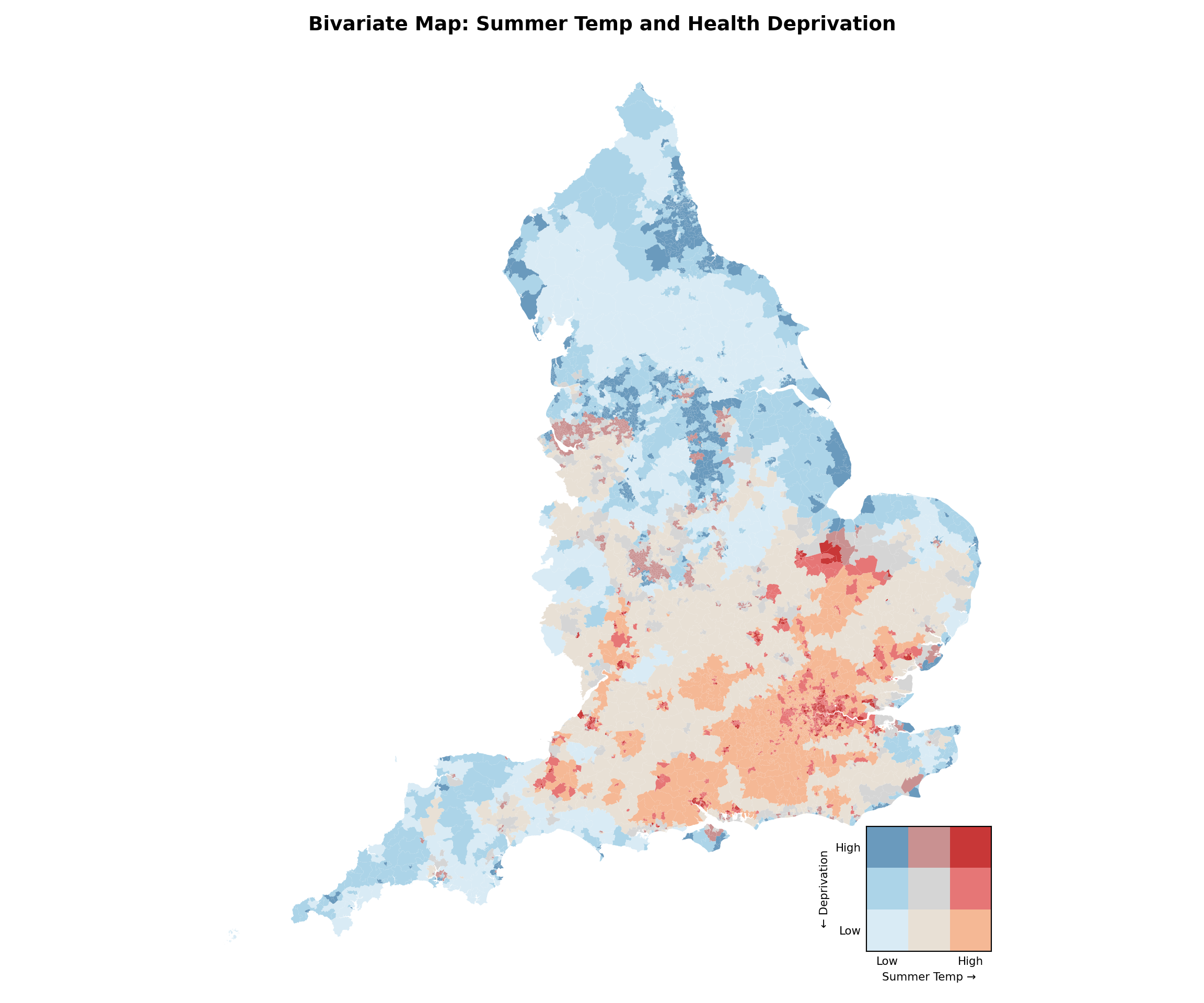
Plot maximum temperature vs. health rank and highlight hotspots. Hotspots appear in the bottom-left quadrant: low temperature (coldest days) + high deprivation.
# --- Create bivariate classes ---# Merging back to geospatial datamsoa_final_clean = msoa_final_clean.merge(msoa_uk[["data_zone_code","geometry"]], left_on="msoa21cd", right_on="data_zone_code", how="left")msoa_bi = msoa_final_clean.copy()msoa_bi = gpd.GeoDataFrame(msoa_bi, geometry="geometry")msoa_bi["summer_class"] = pd.qcut( msoa_bi["summer_max_tmp"], q=3, labels=[1, 2, 3] # 1 = low, 3 = high)msoa_bi["health_class"] = pd.qcut( msoa_bi["health_rank_msoa"], q=3, labels=[3, 2, 1] # Reversed: 3 = most deprived (low rank))msoa_bi["bi_class"] = ( msoa_bi["summer_class"].astype(str) +"-"+ msoa_bi["health_class"].astype(str))# --- Define palette ---bi_palette = {"1-1": "#D9EBF5", # low heat, low deprivation"2-1": "#E8E0D5", # medium heat, low deprivation"3-1": "#F5B895", # high heat, low deprivation"1-2": "#ACD4E8", # low heat, medium deprivation"2-2": "#D5D5D5", # medium heat, medium deprivation"3-2": "#E67676", # high heat, medium deprivation"1-3": "#6A9ABD", # low heat, high deprivation"2-3": "#C99191", # medium heat, high deprivation"3-3": "#C83737", # high heat, high deprivation}# Map colors to datamsoa_bi["color"] = msoa_bi["bi_class"].map(bi_palette)# --- 3. Create map ---fig, ax = plt.subplots(figsize=(12, 10))msoa_bi.plot( ax=ax, color=msoa_bi["color"], edgecolor="none")ax.set_title("Bivariate Map: Summer Temp and Health Deprivation", fontweight="bold", fontsize=14)ax.set_axis_off()# --- Create inset legend (3x3 grid) ---ax_legend = inset_axes( ax, width="15%", height="15%", loc="lower right", borderpad=2)# Build legend gridlegend_grid = np.zeros((3, 3), dtype=object)for i, health inenumerate([3, 2, 1]): # y-axis: top = most deprivedfor j, summer inenumerate([1, 2, 3]): # x-axis: left = low temp legend_grid[i, j] = bi_palette[f"{summer}-{health}"]# Convert to RGB for imshowfrom matplotlib.colors import to_rgbrgb_grid = np.array([[to_rgb(c) for c in row] for row in legend_grid])ax_legend.imshow(rgb_grid, origin="upper")ax_legend.set_xticks([0, 1, 2])ax_legend.set_yticks([0, 1, 2])ax_legend.set_xticklabels(["Low", "", "High"], fontsize=8)ax_legend.set_yticklabels(["High", "", "Low"], fontsize=8)ax_legend.set_xlabel("Summer Temp →", fontsize=8)ax_legend.set_ylabel("← Deprivation", fontsize=8)ax_legend.tick_params(length=0)plt.tight_layout()
<string>:2: UserWarning: This figure includes Axes that are not compatible with tight_layout, so results might be incorrect.
plt.show()
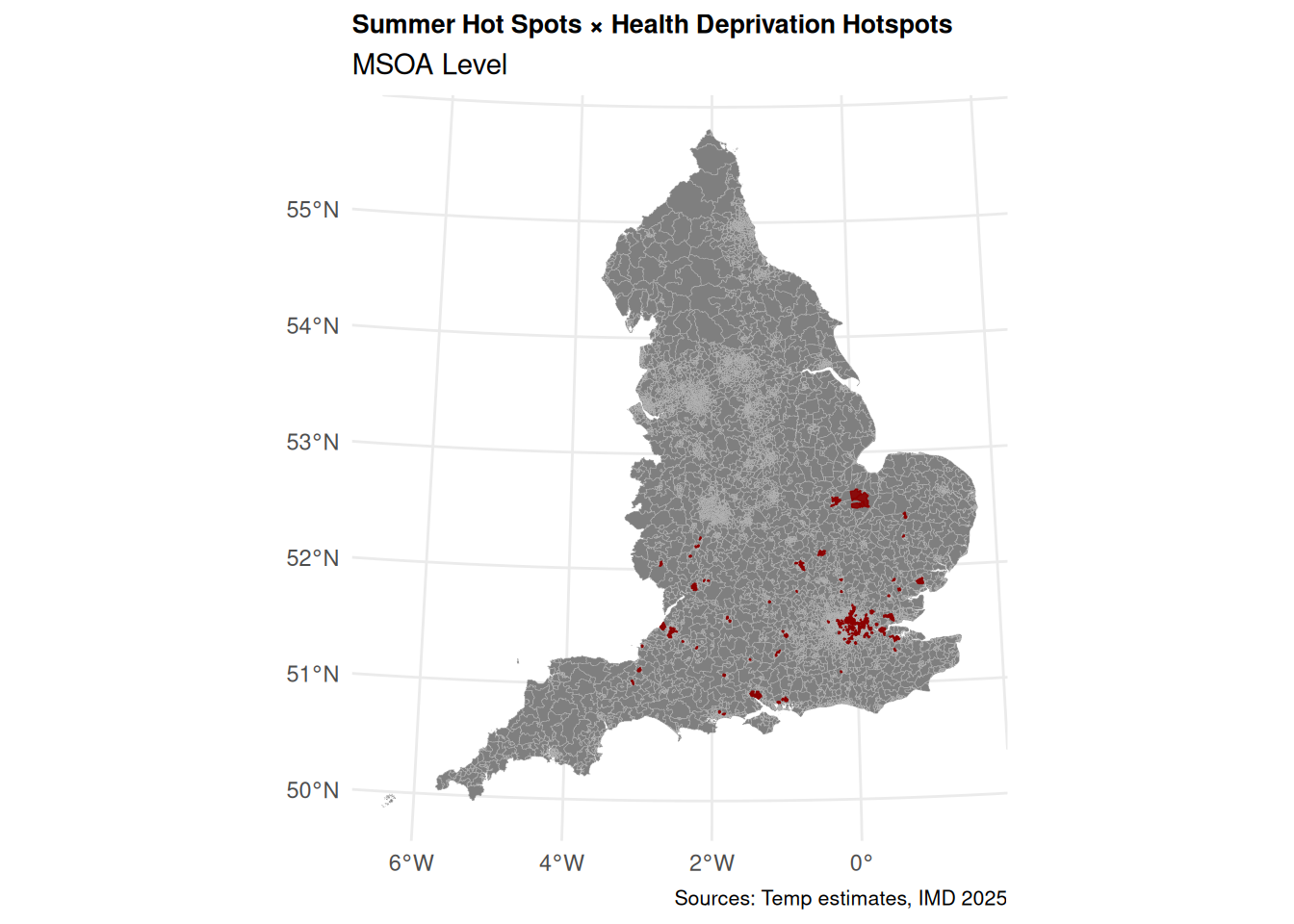
Highlight hotspots on a map
We can highlight hotspots on top of a greyscale map. Immediately shows where the worst areas are. MSOAs in red are where hottest temperatures overlap with high health deprivation. What does this actually tell us?
Other things
Now it’s your turn to explore one of our other data products! There’s a lot more to investigate here. Some ideas to get you started:
Urban vs. Rural Differences: Examine how heat and deprivation vary between urban and rural areas given that at first glance there seems to be a clear urban heat island effect.
Other IMD Measures: explore links between temperature and other aspects of deprivation, such as:
Education levels
Housing in poor condition
Mental health
Other Imago data: Flooding or Sun Probability Framework.